I successfully setup docker images from your how to and they running fine.
I add 277 IPs for scan in single scan and after 21% he stoped, i can resume, but i would like to automate this process and with this behaviour i cannot.
Virtual machine have:
30 vCPU
21GB of RAM
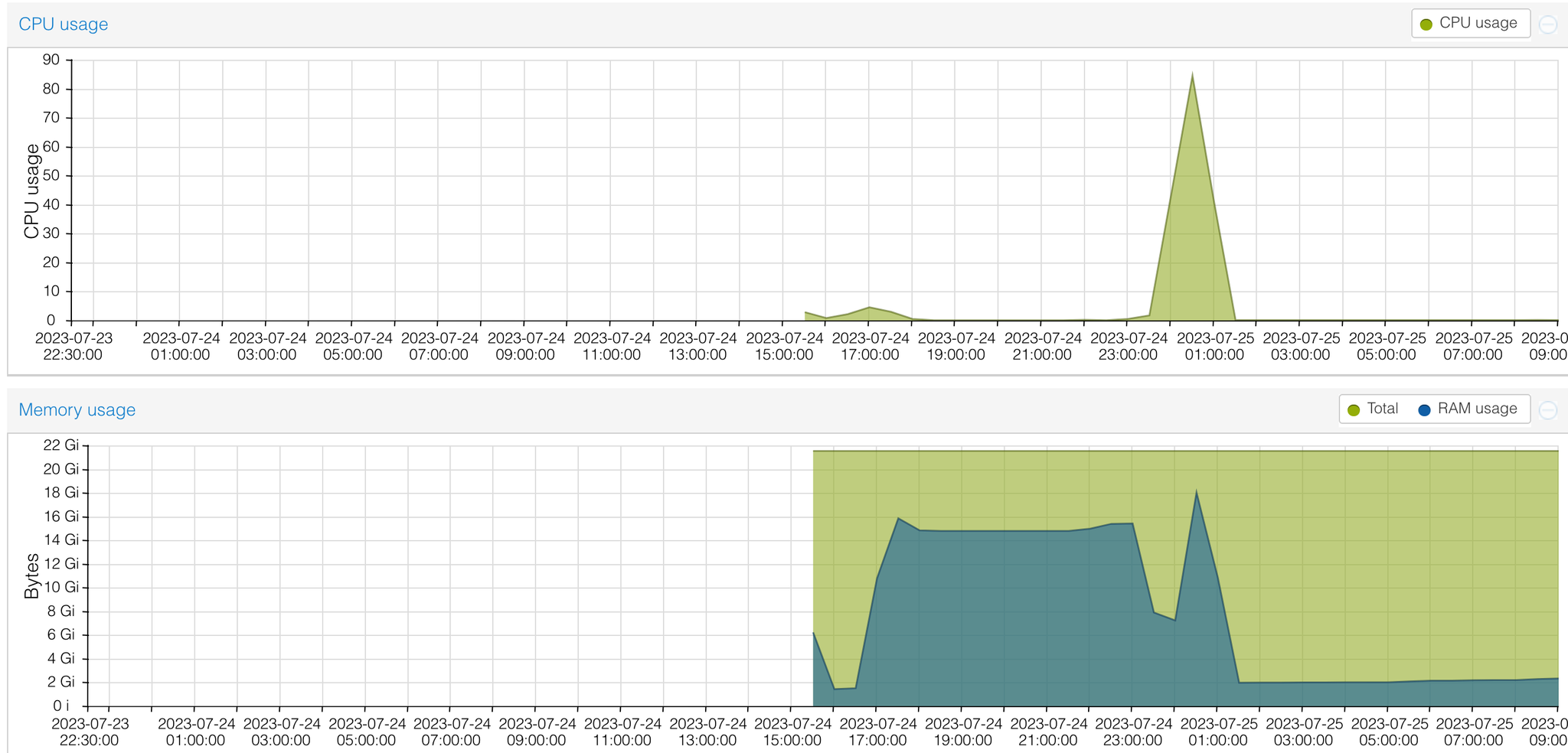
here is graph of load from scan
same… i do not understand what happening.
Can be maybe one IP the problem? maybe it have many services on it and request too much resources?
I successful finish the scan for ±20 IPs …
ok, move to another installation, standalone (without docker) on Kali distribution.
I got same issue, cannot run bigger scan then 20 IPs (not precise number), all the time he run out of RAM, tried overcommitment with 1 and 2 and it is same (with 2 he got interrupted), cannot finish.
Is it possible that there is something on IPs which i scan?
I cannot believe that i cannot out of the box scan subnet…
I supporse your installation does have a memory leak or other issue. I would try with a Greenbone Trial Container on VirtualBox first. You can use the community feed just out of the box with the Trial. If this is working, you have a setup / build / machine issue.
If not enable debug and check why you are running out of memory.
i have proxmox as virtual env. do not have vmware or virtualbox
I just tried compile from source and it is same!
seems that community version is limited to ~20 IPs per scan to finish successful (without interruption) …
Ok, withdrawn by this experience, i will automate process with bulk scanning (20 IPs per scan).
I was used for single scan:
and welcome to this community forums. If there is a memory leak in the scanner you could open up a new issue over here with detailed instructions how to reproduce: