In our organization, we have a very sparse /16 subnet. To allow for this in OpenVAS, I’ve had to break up scans into many smaller scans and schedules into many smaller schedules for all those scans.
The operations team has asked if our scans can be more granular, following the logical organization of our networks, so that application clusters for example, can be identified. This simplifies addressing reports, or suspending scans for sensitive applications.
This would be great, except that each scan can take a very different amount of time. Some take seconds, some take 4+ hours. Planning to have so many scans which do not overlap and can be jig-sawed into a scan schedule is a complex task.
E…g, if I currently have an 8 hour scan window scheduled for: “Production Subnet A” of a /22 subnet
Then I subdivide it into a bunch of scans:
Production Subnet A cluster alpha
Production Subnet A cluster beta
Production Subnet A cluster gamma
Production Subnet A cluster delta
Production Subnet A cluster phi
Production Subnet A load balancers
Production Subnet A switches
Production Subnet A cluster beta databases
Production Subnet A log infrastructure
etc.
Could I assign them all to the same, single 8-hour schedule?
Will it scan simultaneously? will it honor limits on simultaneous hosts per scanner and spread out the load? Will it hit “cluster alpha” excessively even if hosts are randomized? Will it finish alpha before moving on to beta?
Each scan task will begin at the scheduled time for that scan task. If they are all configured with same schedule object, they will all start at the same time. The Maximum concurrently scanned hosts is configured per scan task and as far as I know this will not be calculated between scan tasks.
This could ensure that tasks taking too long, or longer than usual would be halted at a certain point. Not sure if that helps, but maybe an option to avoid network overload.
This won’t work because we don’t know how long any given scan will take.
We could break them all up, run the scans, measure them, create individual windows for each scan
e.g.,
Production Subnet A cluster alpha. - 1h at 8:00
Production Subnet A cluster beta. - 30m at 8:30
Production Subnet A cluster gamma. - 1h at 9:30
Production Subnet A cluster delta. - 20m at 9:50
Production Subnet A cluster phi. - 3h at 12:50
Production Subnet A load balancers - 30m at 13:20
Production Subnet A switches - 30m at 13:50
Production Subnet A cluster beta databases - 2h at 15:50
Production Subnet A log infrastructure - 2h at 17:50
This is turning into a lot of work just to keep these reports separate. It’s also prone to problems, e…g, what if cluster alpha is expanded and needs 1h 30m? All the schedules need to be rejiggled.
This wouldn’t be so bad if I could configure it as easily as writing the schedule above, but having to click through the GUI and fiddle with parameters in response to failed scans… not great.
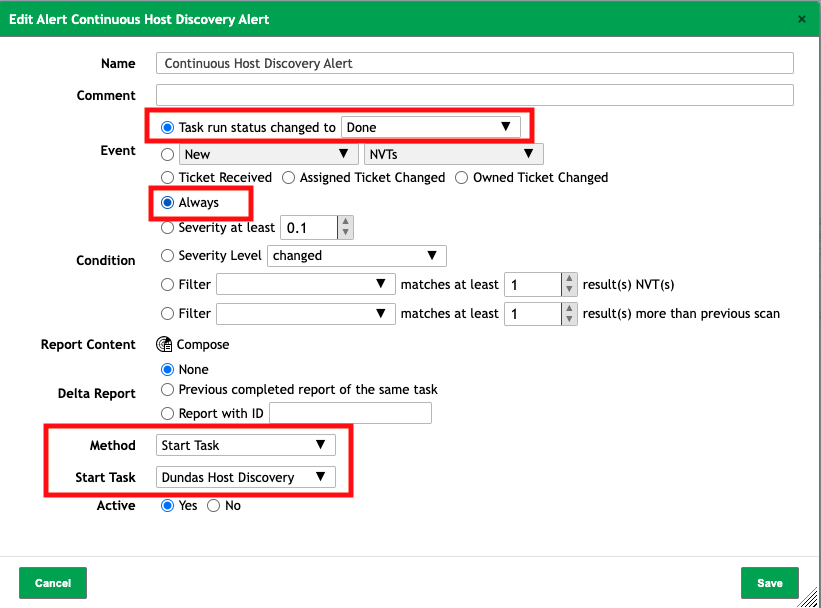
I came across this option to create an alert that will trigger each time a scan task is completed, and will simply start the same scan task or a different one (for your use case this can be the next cluster). This can be used to continuously loop a scan task such as monitoring for rouge hosts, or used to trigger a reliable schedule such as the one you would like. This method essentially ensures that the first scan is completed before starting the next. one.
See the appropriate alert config below:
Event: when the task with the alert configured completes
Beyond this functionality, the capabilities of Greenbone can be further configured more granularly when you start to use python-gvm to interact with GMP protocol directly. This removes the limitations imposed by the web interface and gives you all the powers of additional Python libraries.