I’ve been trying to find a good way to scan all private IP ranges in order to detect new/anomalous hosts that may appear in my infraestructure.
So far I’ve created the targets (4368 targets, since the host limit per target is 4096) using a custom script. And will do the same for the tasks as long as I figure the “scheduling” thing out.
The problem is: how can I schedule them so that there is only 1 of them executed at a time, but also the scans execute again once they are done?
This is a good idea for continuously monitoring your network for rouge devices. You can accomplish this by:
Create a Host Discovery scan specifying a Host as a CIDR or IP range that is appropriate for your private network host range, usually CIDR /24 such as 192.168.1.0/24.
You should select the appropriate Alive Test and port range in the target object that is used for the scan task to suit your needs.
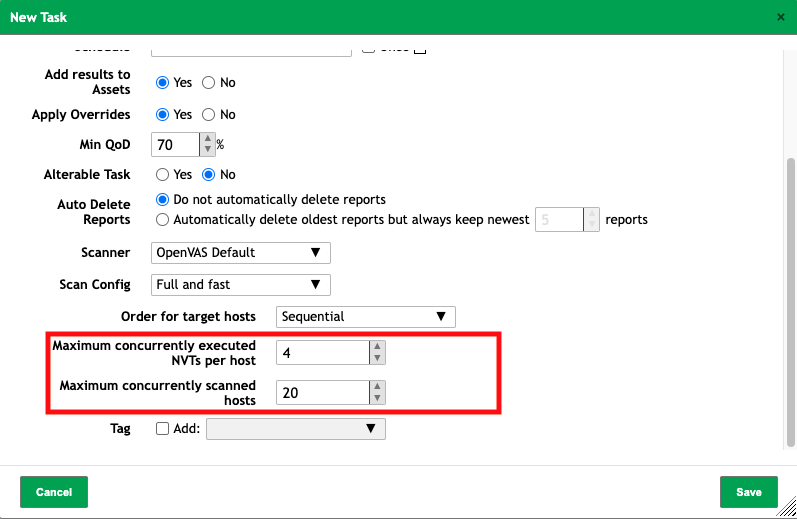
You can’t limit the NVT’s per host or concurrently scanned hosts in the Scan Wizards, but you can when creating a new Scan Task without the Wizard. Set those both to 1 and you will only scan hosts one at a time.
Configure an alert to automatically start the same network discovery scan task each time the scan task is status is “Done” (when it completes). This will continuously run the same scan task that is checking for rouge hosts.
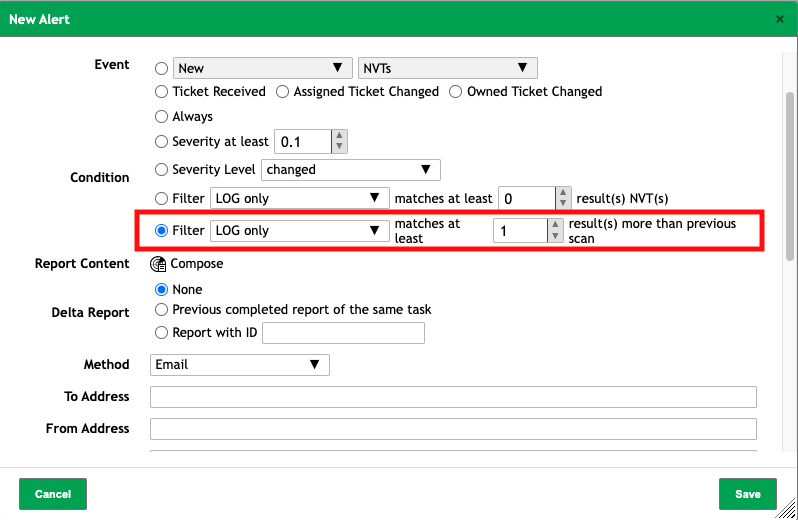
Then create a filter to limit the scan results to LOG only since host discovery only produces log results.
Create an alert with the Log filter combination to automatically notify you if there is a change (delta) between the completed scan and a baseline host discovery scan.
This is a basic way of alerting if a new host is found on the network.
However, this is not the most robust method just mean to relay a general approach. For really higher degree assurances I think it’s appropriate to create either a better filter, that will exclude known hosts in a more reliable way or create a python-gvm script to evaluate the results in more detail than just relying on a count of delta scan results.
First of all, thanks for your detailed response, I’m sure many people will find it useful.
My initial idea was to ingest the results to Elasticsearch and implement the alerting there, but for anyone that doesn’t have an Elasticsearch instance running, that looks like a very good solution!
Although the main problem for me is still there: scheduling 4300 tasks at the same time. I have tried myself and found out that it “kind of” crashes the service, making even the login service unavailable.